
QUBIC BLOG POST
How Do We Measure the Intelligence of a Machine? The g Factor, ARC-AGI, and the Future of AI Evaluation
Written by

Qubic Scientific Team
Published:

Listen to this blog post
Neuraxon Intelligence Academy — Volume 10
By the Qubic Scientific Team

ARC-AGI-3: The first interactive benchmark measuring whether AI can genuinely learn, not just recite. Source: ARC Prize Foundation.
If we build an artificial system and want to know whether it is intelligent, what exactly do we measure? We think we know when we hear that ChatGPT-5 announces it has beaten DeepSeek and then that Claude sweeps Gemini.
But the question is still there, intact. Measuring artificial intelligence is not measuring speed or temperature. We have no unit of measurement, as strange as that may seem.
In psychology we have been dealing with this problem for over a century. Artificial intelligence has been at it for a decade. And it does so in a hurry, with a lot of money at stake and with a constant temptation: to declare victory.
The g Factor: A Single Number to Summarize General Intelligence
At the beginning of the 20th century, Charles Spearman realized that when a child performed well in one subject, they tended to perform well in the others, even if they were subjects with no apparent relation. The scores correlated with one another, all of them positively. He called that pattern the positive manifold, and he deduced that there must be a common latent factor behind all those disparate abilities: the factor g, or general intelligence (Spearman, 1904).
The idea is seductive. If all cognitive tests load onto a single factor, it is enough to extract that factor through factor analysis to have a summary measure of general capacity. In human practice, that first factor usually explains between 40 and 50 % of the variance in performance (Detterman & Daniel, 1989; Deary et al., 2009).
But watch out, because here lies the first trap. The g factor is populational. It does not measure the individual, but variance within individuals (Hernández-Orallo et al., 2021). To say that a specific subject has so much g is, strictly speaking, a mistake. g emerges when comparing many subjects, not when examining one. Like personality, you are the most extroverted of your age group. And you remain so at 50 relative to your group, even if in intensity you are less extroverted than at 20.
What Does IQ Really Measure? Understanding Intelligence Scores
But then, what does IQ measure?
It measures a relative position. The scale is calibrated on a sample with mean 100, standard deviation 15. An IQ of 130 is not an absolute amount of intelligence stored inside someone's head; it is the assertion that this person is two standard deviations above the mean of their normative group. The number is attached to the individual, yes, but its meaning is populational. It is a position in a ranking, not a content.
Your height is absolute: you are 180 centimeters tall even if you are the last human being on Earth. Your IQ is not: being above the mean requires a mean, and a mean requires others. No one can be more intelligent than the average on a desert island.
Now one understands why transferring this to AI is so delicate. When someone computes a g for a set of large language models (LLMs), that factor is an artifact of the set they chose. We are measuring a position in a table, and we present it as if it were an internal property of the system.
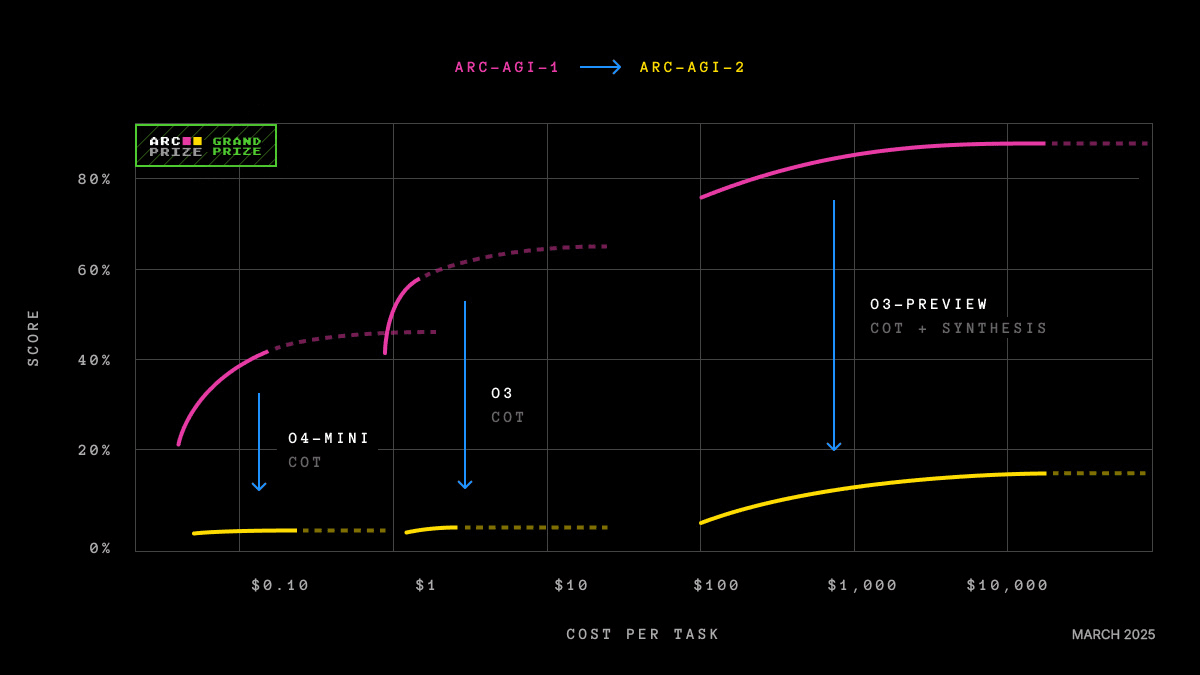
Log-linear scaling alone cannot close the gap between AI and human reasoning efficiency. Source: ARC Prize Foundation
Applying the g Factor to Artificial Intelligence: A Dangerous Temptation
The temptation to transfer all of this to AI was irresistible. Gignac and Szodorai proposed that, if the performance of models across varied tasks correlates positively, it should be possible to identify a general factor of capacity in artificial systems as well. And indeed, several recent works apply factor analysis to test batteries in LLMs and find a unidimensional g factor that remains stable across models, batteries and extraction methods (Ilić, 2023). It sounds like confirmation. It is wise to be suspicious.
The appearance of a dominant first factor does not prove that there exists a general capacity analogous to the human one. It proves that the scores of those models covary. And they covary for a very shallow reason: they share architecture, they share training corpus, they share optimization recipes. A large, well-trained model does everything better than a small, poorly trained one, across all tasks at once. That is enough to manufacture a beautiful positive manifold that tells us nothing about cognitive generality. It tells us about the scale of computation. WATCH OUT: The factor we extract may simply be a factor of size disguised as intelligence.
The brain, moreover, does not concentrate intelligence in a single module. A multitude of specialized subsystems process in parallel and, when a piece of information wins the competition, it becomes globally available to the rest of the system, which can then recombine it for new purposes (Baars, 1988; Dehaene & Changeux, 2011). What we call generality is global availability: putting a piece learned in one context at the service of a problem in another. It is not a stored scalar number; it is a pattern of access and integration. This is the kind of functional architecture that Neuraxon tries to emulate — modular subsystems with continuous-time dynamics and multi-timescale plasticity, rather than a monolithic transformer.
François Chollet and the Modern Approach: Measuring What You Still Don't Know How to Do
Against the psychometric legacy, François Chollet proposed in 2019 a conceptual turn. His argument, in On the Measure of Intelligence, is that we were measuring the wrong thing.
Traditional AI benchmarks reward skills, specific competencies on concrete tasks. But a skill can be bought with data and computation: it is enough to train sufficiently on a task to master it. Intelligence, Chollet maintains, is not skill, but efficiency in the acquisition of skills: how much you learn from how little, when facing a genuinely new task (Chollet, 2019).
Intelligence is what you do when you don't know what to do.
This distinction changes everything. A system that solves a million problems because it has seen ten million similar ones is not intelligent. An intelligent system is the one that, facing a problem for which it could not prepare, discovers the structure and adapts with few examples. The measure stops being the final result and becomes the slope of learning.
ARC-AGI: The Benchmark That Tests Genuine AI Reasoning
ARC-AGI was born from that idea, and its most recent version, ARC-AGI-3, takes it further. It is not a question-and-answer test. It is a set of interactive environments, like mini-videogames, in which the agent explores an unknown world, deduces what the objective is without being told in natural language, builds a model of the environment and adapts its strategy step by step (ARC Prize, 2025).
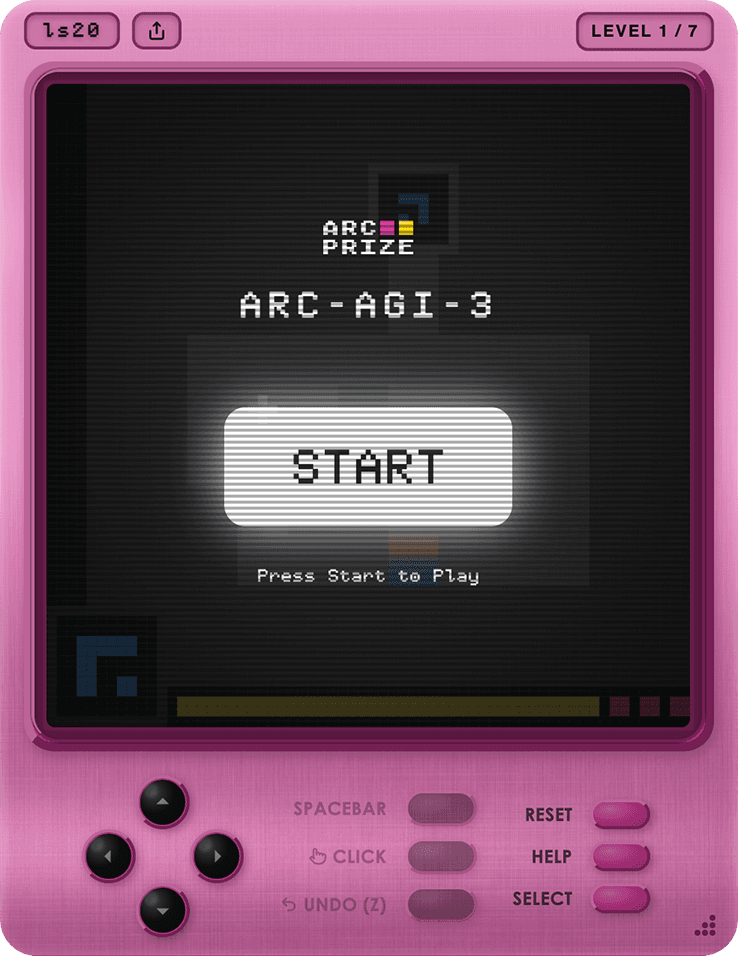
An ARC-AGI-3 game environment. Agents must explore, learn rules, and discover objectives, with zero instructions. Humans score 100%; frontier AI scores below 1%. Source: ARC Prize Foundation.
The design principles are explicit: environments 100 % solvable by humans, with no preloaded knowledge or hidden instructions, and with enough novelty to prevent memorization. What is scored is not getting it right, but efficiency in the acquisition of skill over time.
It is the opposite of the g factor: instead of looking for what a system already masters and summarizing it, it looks for what it still does not know how to do and measures how much it costs it to learn it.
Data Contamination: Why LLM Benchmark Scores Are Inflated
The ultimate reason why Chollet's approach matters, and why the g factor applied to LLMs is so slippery, has a technical name: data contamination. If the exam, or something almost identical, was in the notes the student studied, their grade does not measure what they can reason. It measures what they have memorized.
Language models are trained on books, forums, code repositories, articles, practically all the available text. The benchmarks with which we then evaluate them are published on the internet. The conclusion is that fragments of the tests end up inside the training data, which violates the separation between training and evaluation and inflates the scores (Xu et al., 2024; Deng et al., 2024). Empirical audits have detected contamination levels ranging from 1 % up to 45 % in widely used benchmarks, and the problem grows over time (Li et al., 2024).
It is not a minor problem of a couple of leaked questions. In benchmarks as cited as MMLU or GSM8K, part of what we interpret as reasoning may be pure memorization (Chen et al., 2025). When decontamination techniques are applied that rewrite the leaked items without altering their difficulty, accuracy drops: in one study, 22.9 % on GSM8K and 19.0 % on MMLU (Zhu et al., 2024).
Paraphrased items, or even ones translated into another language, dodge the superficial-overlap detectors and continue to inflate the results (Yang et al., 2023; Yao et al., 2024). The usual solutions (paraphrasing, translating, tweaking the context) are assumed to be effective without having been validated rigorously. And for most open models we cannot even check anything, because their training data is not published. We are grading exams without knowing what the student studied.
Here one understands why ARC-AGI chose the path it chose. An interactive, novel environment, with no natural-language instructions and designed to prevent brute-force memorization is, by construction, resistant to contamination.
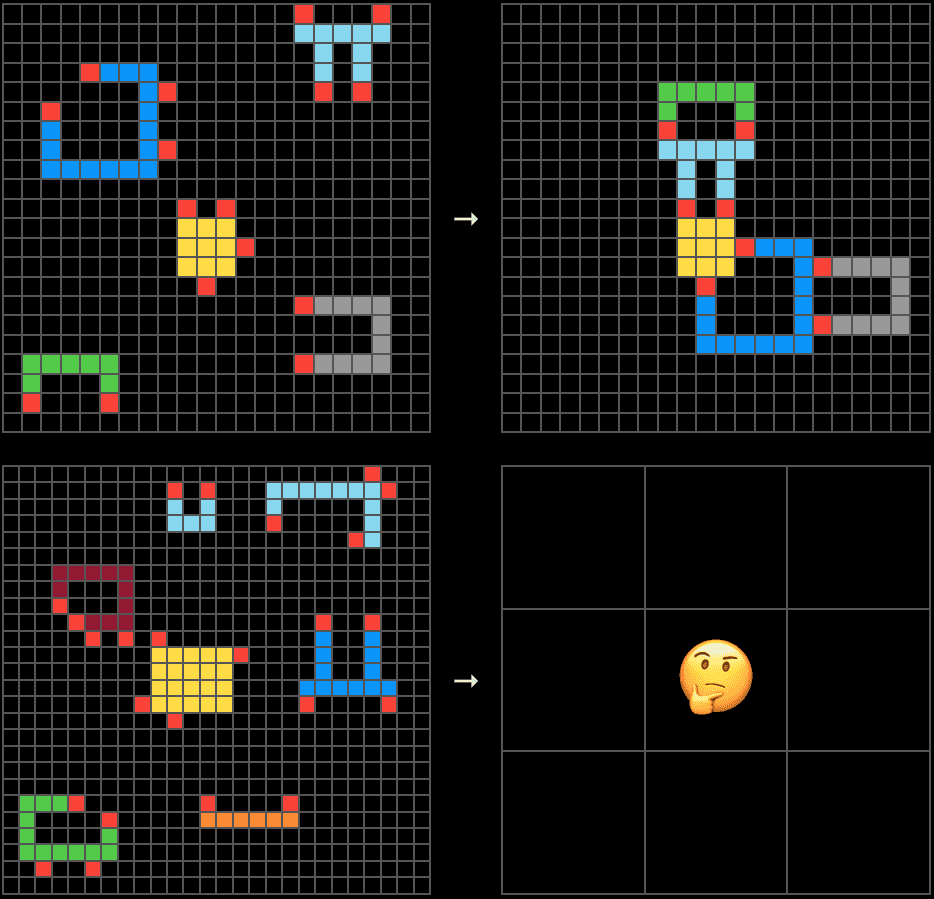
An example ARC-AGI task requiring compositional reasoning. Tasks like these are designed to be unsolvable through memorization alone. Source: ARC Prize Foundation
So, What Should We Measure to Evaluate Machine Intelligence?
The g factor is a populational property that, applied to models that share architecture and corpus, runs the risk of measuring the scale of computation and not generality. The lesson for whoever builds artificial systems is not to choose between the g factor and ARC-AGI as if they were rival teams. It is to understand what question each one answers. A factor analysis can be useful to describe the internal structure of a system's performance, as long as the first factor is not confused with an essence of intelligence. And an ARC-type protocol is indispensable for what really matters: checking whether the system generalizes beyond what it saw, or merely recites.
When we evaluate a system only by its final answer, we are measuring it with our eyes closed to its temporal dimension: planning, the updating of beliefs, the integration of evidence across many steps. It is exactly what ARC-AGI-3 decided to score, and exactly what a static exam cannot see.

The ARC-AGI-3 Technical Report details the benchmark's design, its efficiency-based scoring framework, and human calibration methodology. Read the full paper at arcprize.org. Source: ARC Prize Foundation
Why Brain-Inspired AI Architectures Like Neuraxon Take a Different Path
If intelligence is not a stored number but the efficient integration of specialized subsystems, as suggested by the parieto-frontal integration theory (P-FIT) and the global availability of the workspace in the brain…
If that integration is above all a temporal phenomenon, with time scales…
Then a system built on modular architectures with functional spheres, plasticity across multiple temporal scales and continuous dynamics does not need to be evaluated by asking it to recite answers.
The correct question is not how many benchmarks it beats, but with what efficiency it acquires new behavior, over time, in environments for which it was not prepared. That is the direction Neuraxon tries to take. To compute time – that is, adaptation – not memorized answers that simulate being a good student, when in reality, it already knows the questions.
References
Chollet, F. (2019). On the Measure of Intelligence. arXiv:1911.01547.
Deary, I. J., Penke, L., & Johnson, W. (2009). The neuroscience of human intelligence differences. Nature Reviews Neuroscience.
Dehaene, S., & Changeux, J.-P. (2011). Experimental and theoretical approaches to conscious processing. Neuron, 70(2), 200–227.
Detterman, D. K., & Daniel, M. H. (1989). Correlations of mental tests with each other and with cognitive variables. Intelligence.
Gignac, G. E., & Szodorai, E. T. (2024). Defining and identifying a general factor of ability in AI systems.
Guttman, L. (1955). The determinacy of factor score matrices with implications for five other basic problems of common-factor theory. British Journal of Statistical Psychology.
Hernández-Orallo, J., et al. (2021). General intelligence disentangled via a generality metric for natural and artificial intelligence. Scientific Reports.
Honey, C. J., et al. (2012). Slow cortical dynamics and the accumulation of information over long timescales. Neuron, 76(2), 423–434.
Ilić, D. (2023). Unveiling the General Intelligence Factor in Language Models: A Psychometric Approach. arXiv:2310.11616.
Jung, R. E., & Haier, R. J. (2007). The Parieto-Frontal Integration Theory (P-FIT) of intelligence. Behavioral and Brain Sciences.
Spearman, C. (1904). "General intelligence" objectively determined and measured. American Journal of Psychology, 15, 201–293.
Roberts, M., et al. (2024). Temporal evidence of contamination from training cutoff dates.
Schönemann, P. H. (2008). A Rejoinder to Mackintosh and some Remarks on the Concept of General Intelligence. arXiv:0808.2343.
Xu, C., et al. (2024). Benchmark data contamination of large language models: a survey.
Yang, S., et al. (2023). Rethinking benchmark and contamination for language models with rephrased samples.
Zhu, Q., et al. (2024). Inference-Time Decontamination: Reusing leaked benchmarks for LLM evaluation. Findings of EMNLP 2024.
ARC Prize (2025). ARC-AGI-3: An interactive reasoning benchmark. Technical Report.
Explore the Full Neuraxon Intelligence Academy Series
This is Volume 10 of the Neuraxon Intelligence Academy by the Qubic Scientific Team. If you are just joining us, explore the complete series to build a full understanding of the science behind Neuraxon, Aigarth, and Qubic's approach to brain-inspired, decentralized artificial intelligence:
NIA Volume 1: Why Intelligence Is Not Computed in Steps, but in Time — Explores why biological intelligence operates in continuous time rather than discrete computational steps like traditional LLMs.
NIA Volume 2: Ternary Dynamics as a Model of Living Intelligence — Explains ternary dynamics and why three-state logic (excitatory, neutral, inhibitory) matters for modeling living systems.
NIA Volume 3: Neuromodulation and Brain-Inspired AI — Covers neuromodulation and how the brain's chemical signaling (dopamine, serotonin, acetylcholine, norepinephrine) inspires Neuraxon's architecture.
NIA Volume 4: Neural Networks in AI and Neuroscience — A deep comparison of biological neural networks, artificial neural networks, and Neuraxon's third-path approach.
NIA Volume 5: Astrocytes and Brain-Inspired AI — How astrocytic gating transforms neural network plasticity through the AGMP framework in Neuraxon.
NIA Volume 6: Conscious Machines vs Intelligent Organisms: AI Consciousness Explained — Explores AI consciousness through the lens of Global Workspace Theory, Integrated Information Theory, and predictive coding.
NIA Volume 7: Conway's Game of Life, Artificial Life, and Digital Ecosystems — The science behind Qubic, Aigarth, and Neuraxon's emergent complexity and self-organized criticality.
NIA Volume 8: Brain Criticality and the Branching Ratio in Neural and Artificial Networks — Why a branching ratio near 1 and self-organized criticality are bioinspired design principles in Neuraxon.
NIA Volume 9: The Origins of the g Factor: From Education and Neuroscience to Artificial Intelligence — Explores the origins of the g factor across education, neuroscience, and AI.
Qubic is a decentralized, open-source network for experimental technology. To learn more, visit qubic.org. Join the discussion on X, Discord, and Telegram.