
QUBIC BLOG POST
Neural Networks in AI and Neuroscience: How the Brain Inspires Artificial Intelligence
Written by

Qubic Scientific Team
Published:

Listen to this blog post
Neuraxon Intelligence Academy — Volume 4
The word network shows up constantly in both neuroscience and artificial intelligence. But despite sharing the same label, biological neural networks and artificial neural networks are fundamentally different systems. To understand what each one actually does, and where a third approach fits in, we need to look at the architecture and behavior of networks at every level.
Biological Neural Networks: How the Brain Processes Information
A biological neural network is a system of interconnected neurons whose function is to process information and generate behavior. These networks are dynamic. They stay active over time, even when we are not consciously engaged in any task. They carry an energetic cost, which in the case of the human brain is remarkably low for the complexity it produces.
Biological networks integrate both internal and external signals using their own language: time-frequency. Think of a musical band with multiple instruments playing at different rhythms. The bass drum carries the tempo, the bass plays two notes per beat, and the cymbals fill in the sixteenth notes. The melody moves freely without losing the beat. The musicians couple their scores at different rhythms that fit together perfectly. These are nested frequencies, and this is exactly how brain networks function. The time-frequency language of different networks nests within itself, a concept known as cross-frequency coupling.
From Single Neurons to Massive Networks
Everything begins with the neuron. That single nerve cell generates an action potential, a brief electrical impulse that propagates along the axon. The neuron receives signals through the dendrites, integrates them in the soma, and transmits the signal if it surpasses a threshold. We covered this process in detail in NIA Volume 1: Why Intelligence Is Not Computed in Steps, but in Time and NIA Volume 2: Ternary Dynamics as a Model of Living Intelligence.
Neurons connect to other neurons through chemical synapses, where neurotransmitters are released (see NIA Volume 3: Neuromodulation and Brain-Inspired AI), or through electrical synapses, where current passes directly between cells. To form networks, many neurons interconnect and create recurrent circuits. But this integration is non-linear, meaning the response of the whole does not equal the simple sum of its parts. The magnitude is staggering: the human brain contains approximately 86 billion neurons and somewhere between 10¹⁴ and 10¹⁵ synapses (Azevedo et al., 2009).
Small-World Properties and Excitation-Inhibition Balance
At the topological level, these networks display small-world properties: high local clustering combined with short global connections. This architecture enables efficient communication across the brain while maintaining specialized local processing.
The functioning of biological neural networks depends on the balance between excitation and inhibition. If excitation dominates, activity destabilizes. If inhibition dominates, the network goes silent. Dynamic stability arises from the balance between both forces. This balance is maintained through synaptic plasticity, the mechanism that allows the strength of connections to change based on experience. On top of that, neuromodulation adjusts circuit gain, controlling how strongly an input produces an output (Marder, 2012). In a threatening situation, for example, noradrenaline increases sensory sensitivity and the capacity for rapid learning.
Multiple Temporal Scales and Cerebral Cortex Brain Function
Networks operate at multiple temporal scales simultaneously. At the neuronal level, action potentials fire in milliseconds. Neuronal oscillations unfold in seconds. Synaptic changes develop over hours or days, and structural reorganization happens across years. Everything works in a harmonic, dynamic, and intertwined pattern.
But not everything communicates with everything without structure. The cerebral cortex brain function is organized into specialized networks. The most important include the default mode network, linked to self-reference and thinking about the self and others; the central executive network, linked to direct task execution; the salience network, which detects what is relevant at each moment and allows switching between different modes; the sensorimotor network that sustains voluntary movements; and various attention networks. Humans also possess a distinctive language network, enabling both comprehension and production of language.
In biological networks, no isolated note is a symphony. The symphony emerges from the dynamic pattern of relationships between notes. The brain does not contain things. It does not store memories the way a hard drive stores files. The brain constructs dynamic configurations.
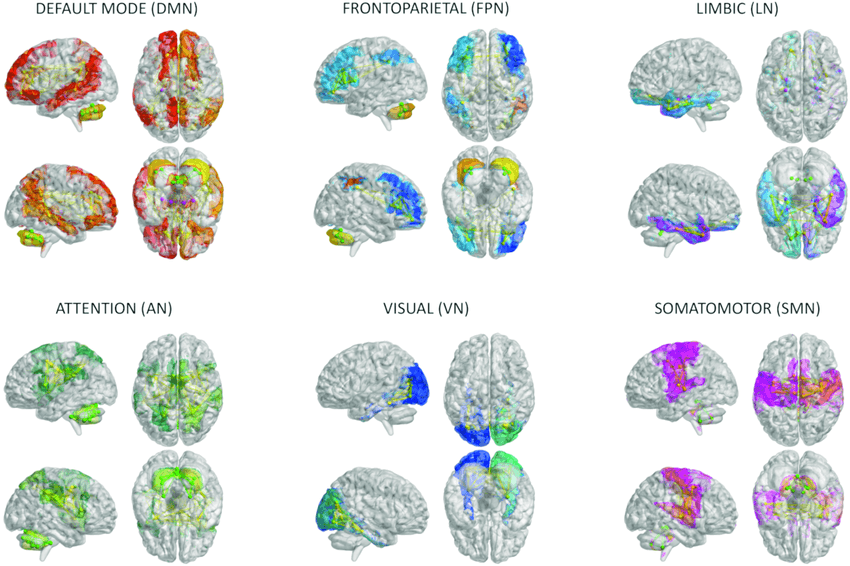
Courtesy from DOI: 10.3389/fnagi.2023.1204134
Artificial Neural Networks: How Deep Learning Models Work
An artificial neural network (ANN) is a mathematical model designed to approximate complex functions from data. It draws abstract inspiration from the brain: it uses interconnected units called "artificial neurons," but these are not cells. They are algebraic operations. Calling an algebraic operation a neuron is arguably an exaggerated extrapolation, and calling language prediction "intelligence" may be equally misleading. But since these are the established terms, it is important to understand them and separate substance from hype.
How an Artificial Neuron Works
Each artificial neuron performs three steps. First, it receives a set of numerical inputs. Then it multiplies each input by a synaptic weight, which is an adjustable parameter. Finally, it sums the results and applies an activation function that introduces non-linearity. Common activation functions include the Sigmoid, which compresses values between 0 and 1, and ReLU (Rectified Linear Unit), which cancels negative values and lets positive ones pass through.
Without non-linearity, the network would simply perform a linear transformation, incapable of modeling complex patterns. ANNs are organized into input layers, where data enter; hidden layers, where data are progressively transformed; and an output layer, which generates the prediction.
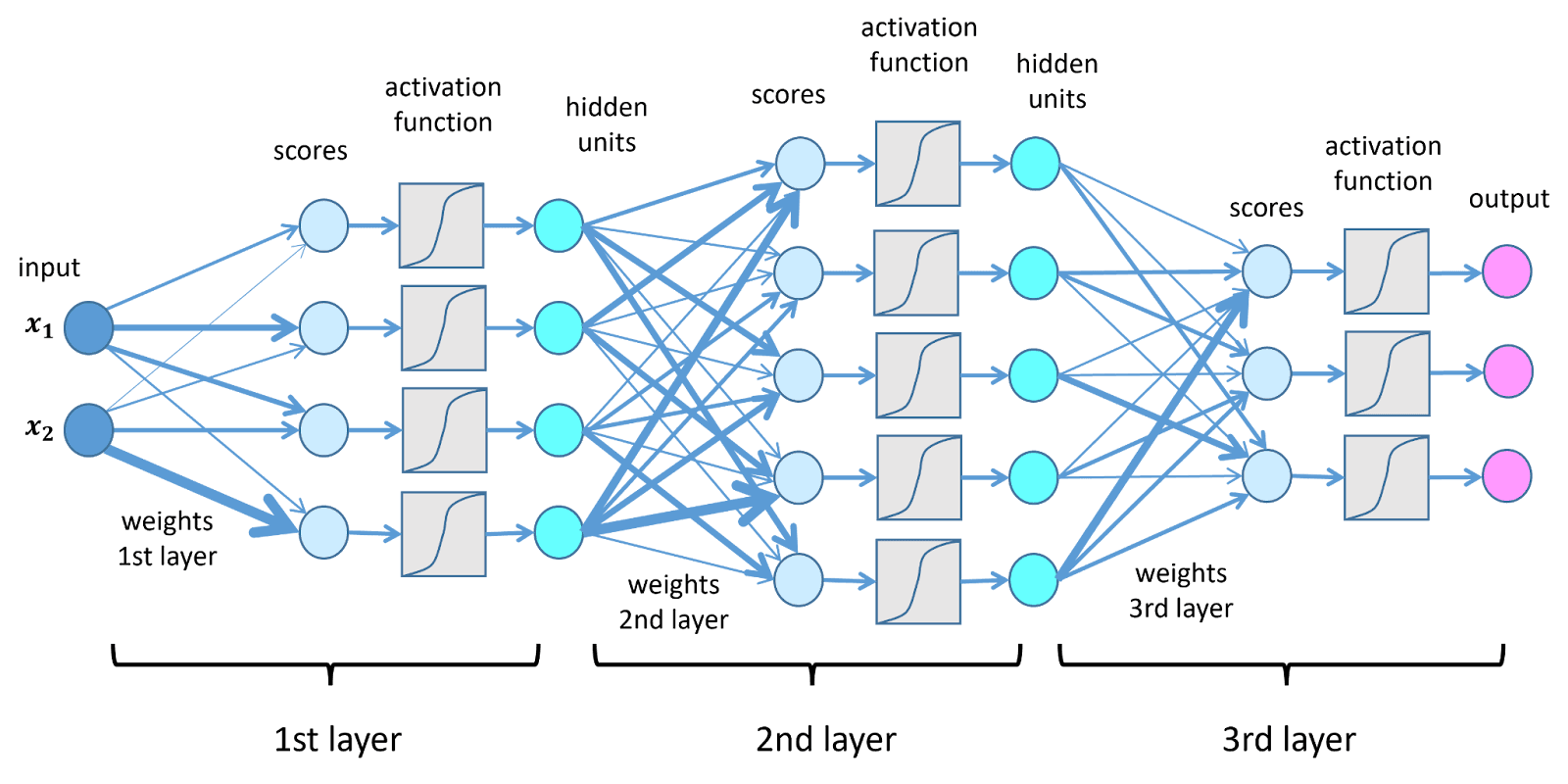
From the Perceptron to Deep Learning
All modern architectures trace their origins to the perceptron (Rosenblatt, 1958), a simple linear neuron with a threshold. Modern deep learning networks can contain hundreds of layers and billions of parameters. But at their core, an ANN functions like an enormous automated spreadsheet that adjusts millions of numerical cells until the output matches the expected result.
Backpropagation and Gradient Descent: How Artificial Networks Learn
Learning in artificial networks does not work the way biological learning does. There is no adjustment of neuromodulators or synaptic intensity based on lived experience. Instead, learning is based on minimizing an error function that quantifies the difference between the network's prediction and the correct answer.
Consider a simple example: the model is asked to complete "Paris is the capital of..." If the prediction is Italy, the error function measures the gap between Italy and France, then adjusts the weights accordingly. The central mechanism behind this adjustment is backpropagation (Rumelhart et al., 1986). This algorithm calculates the error at the output, propagates that error backward layer by layer, and adjusts the weights using gradient descent, a mathematical method that modifies parameters in the direction that reduces the error.
Formally, learning consists of optimizing a differentiable function in a space of many dimensions. If you think of physical space, the dimensions are x, y, and z. But in language, imagine dimensions like singular, plural, feminine, masculine, verb, subject, attribute, noun, adjective, intonation, and synonym. Introduce millions of dimensions and enough computational power, and a model can learn that Paris is the capital of France simply by reducing prediction errors during training.
Architectures of Artificial Neural Networks
Although the terminology overlaps with neuroscience, the process does not resemble how a living system learns. In an ANN, adjustment depends on global calculation and explicit knowledge of the final error. The network needs to know exactly how wrong it was.
If a network learns to recognize cats, it receives thousands or millions of labeled images. Each time it fails, it slightly adjusts the weights. After millions of iterations, the internal pattern stabilizes into a configuration that discriminates cats from other objects. The process is purely statistical. The network does not "understand" what a cat is. It detects numerical correlations in pixels. It does not hold a "world model" of a cat, only matrices of numbers on massive scales. For a deeper look at why this matters, read our analysis of benchmarking world model learning.
There are several key architectures of artificial neural networks. Convolutional networks (CNNs) use spatial filters that detect edges, textures, and hierarchical patterns, making them essential for computer vision. Recurrent networks (RNNs, LSTMs) incorporate temporal memory for processing sequences. And the now-dominant Transformers use attention mechanisms that dynamically weight which parts of the input are most relevant (Vaswani et al., 2017). Transformers currently power most large language models in natural language processing.
The growth of these networks does not happen organically as in living systems. It happens through explicit design and parameter scaling via massive training in high-performance computing centers. Adaptation is limited to the training period. Once trained, the network does not spontaneously reorganize its architecture. Any modification requires a new optimization process. As we explored in That Static AI Is a Dead End, this frozen nature is a fundamental limitation of current AI systems.
Despite sharing the name "network," the similarity between artificial and biological neural networks is limited. The analogy is structural and abstract: both use interconnected units and learning through adjustment of connections. But the brain is an evolutionary, embodied, and self-regulated system. An ANN is a function optimizer in a numerical space.
Between Biological and Artificial Networks: How Neuraxon Aigarth Bridges the Gap
The networks simulated in Neuraxon Aigarth are conceptually positioned between biological networks and conventional artificial neural networks. They are not living tissue, but they are not merely mathematical functions optimized by gradient either. Their objective is to approximate dynamics typical of biological systems, including multiscale plasticity, context-dependent modulation, and self-organization, all within a computational framework built for Qubic's decentralized AI infrastructure.
If in Volume 1 we described self-organized metabolic systems and in Volume 2 we explored differentiable optimizing functions, Neuraxon attempts to incorporate dynamic properties of the former without abandoning the mathematical formalization of the latter.
Trivalent States: Capturing Excitation-Inhibition Balance
Instead of typical continuous activations (real values after a ReLU, for example), Neuraxon uses trivalent states: -1, 0, and +1. Here, +1 represents excitatory activation, -1 represents inhibitory activation, and 0 represents rest or inactivity.
This scheme does not attempt to copy the biological action potential. Rather, it captures the functional principle of excitation-inhibition balance described in the biological networks section above. In the brain, stability emerges from the balance between these forces. In Neuraxon, the discrete state space imposes a dynamic closer to state-transition systems than to simple continuous transformations.
In contrast to classical artificial networks, where activation is a floating-point number without physiological meaning, the trivalent system imposes structural constraints that shape how activity propagates through the network.
Dual-Weight Plasticity: Fast and Slow Learning
Biological neural networks exhibit plasticity at different temporal scales: rapid changes in synaptic efficacy and slower consolidation over time. Neuraxon introduces this idea through two weight components:
w_fast: rapid changes that are sensitive to the immediate environment.
w_slow: slow changes that stabilize repeated patterns over time.
This prevents the system from depending exclusively on a homogeneous weight update like standard backpropagation. Part of learning can be transient, while another part is gradually consolidated. This mechanism introduces a dimension absent in most artificial neural networks: the learning rate is not fixed, but dependent on the global state of the system.
Contextual Neuromodulation Through the Meta Variable
In biological networks, neuromodulators such as noradrenaline and dopamine do not transmit specific informational content. Instead, they alter the gain and plasticity of broad neuronal populations. We explored this in depth in NIA Volume 3: Neuromodulation and Brain-Inspired AI.
In Neuraxon, the variable meta plays a functionally analogous role. It does not encode specific information, but modifies the magnitude of synaptic updating. This approximates the biological principle that learning depends on motivational or salience context. In a conventional artificial network, the gradient is applied uniformly based on error. In Neuraxon, learning can be intensified or attenuated according to internal state or global external signals.
The conceptual difference is significant. In classical deep learning networks, error drives learning. In Neuraxon, error can coexist with a contextual modulatory signal that alters how much is learned at any given moment.
Self-Organized Criticality and Adaptive Behavior
Biological networks operate near a regime called self-organized criticality, where the system maintains equilibrium between order and chaos. This regime allows flexibility without loss of stability.
Neuraxon models this property by allowing the network to evolve toward intermediate dynamic states in which small perturbations can produce broad reorganizations without collapsing the system.
In models such as the Game of Life extended with proprioception that the team is currently developing, the system can receive external signals (environment) and internal signals (its own state, energy, previous collisions). If an agent repeatedly collides with an obstacle, an increase in the meta signal may be generated, analogous to an increase in arousal. That signal temporarily increases plasticity, facilitating structural reorganization.
Here, the network does not learn only because it makes mistakes. It learns because the environment acquires adaptive relevance. The similarity with the brain remains limited: Neuraxon does not possess biology, metabolism, or subjective experience. However, it introduces dynamic dimensions absent in most conventional artificial neural networks, positioning it as a genuinely novel approach to brain-inspired AI on decentralized infrastructure.
The computational power required to run Neuraxon simulations is provided by Qubic's global network of miners through Useful Proof of Work, turning AI training into the consensus mechanism itself.

Scientific References
Azevedo, F. A. C., et al. (2009). Equal numbers of neuronal and nonneuronal cells make the human brain an isometrically scaled-up primate brain. Journal of Comparative Neurology, 513(5), 532-541. DOI: 10.1002/cne.21974
Marder, E. (2012). Neuromodulation of neuronal circuits: Back to the future. Neuron, 76(1), 1-11. DOI: 10.1016/j.neuron.2012.09.010
Rosenblatt, F. (1958). The Perceptron: A probabilistic model for information storage and organization in the brain. Psychological Review, 65(6), 386-408. DOI: 10.1037/h0042519
Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Learning representations by back-propagating errors. Nature, 323(6088), 533-536. DOI: 10.1038/323533a0
Vaswani, A., et al. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30. arXiv: 1706.03762
Brain network images courtesy from: DOI: 10.3389/fnagi.2023.1204134