
QUBIC BLOG POST
RPC 2.0 Qubic Integration Layer Functionality Upgrade
Written by

The Qubic Team
Published:

Listen to this blog post
Integration Layer Revamp
For a while now, Qubic has had an "integration layer" that makes it easy for outside apps like crypto wallets, exchanges, and block explorers to connect to its network. This layer lets these apps do important things like send transactions, check smart contracts, and get information about what's happening on the Qubic network. It's really helpful because developers don't have to learn all the complicated inner workings of Qubic or figure out how to talk directly to its "nodes" (the computers running the network).
However, Qubic is growing fast, and this old integration layer was starting to hit its limits. To keep up with future growth, Qubic began rebuilding this layer at the start of the year. The result is a big upgrade, including a new way to store historical data and upgraded APIs. This new system is built to handle Qubic's expected growth. It officially launched on July 1st, 2025.
While some of the technical details might not be super interesting to the average Qubic user, this new setup is a big deal behind the scenes. It helps make sure everything runs smoothly as Qubic continues to expand.
Integration APIs
The integration layer provides several different APIs. The most important ones are the live API and the archive API.
The live API communicates directly with the Qubic nodes and provides the most current data. It fetches information such as balances and asset data, and it enables users to send transactions and query smart contracts. The nodes provide an up-to-date view of the data for the current epoch. The live API will remain unchanged.
The archive API provides archived data. This data is collected from the nodes and stored in a database. This API will be replaced by the new archive API.
Original solution
The original archive implementation (qubic-archiver) is a fast, monolithic, and specialized solution. It processes the data for every tick, validates it by using quorum data, stores it in an embedded database (pebble), and serves it via GRPC and REST-like endpoints. Redundancy is achieved by running several instances in different data centers in parallel. While this solution still works perfectly fine it is not sufficiently future-proof to handle the expected long-term growth.
Certain challenges need to be solved to ensure long-term sustainability. The most important ones are:
Load => Be able to scale with the growing number of API requests.
Data => Be able to handle large amounts of data.
Features => Be able to provide better access to the data.
Load
Not long ago, at the beginning of 2025, the entire integration layer was required to handle up to 10,000 requests per minute. Just six months later, this number doubled, and we now serve over 20,000 requests per minute during peak times. This load is expected to grow as the Qubic project gains more and more adoption. Furthermore, processing has become more resource-intensive as the tick time has decreased and more transactions have been made.
In order to scale as needed, we decided to split the querying part into a separate application, allowing it to focus on serving requests while the archiver focuses on processing data.
Data
While one year ago the amount of data that we collect was easily manageable we are now store between 600 GB and 800 GB of data per archiver instance, depending on the database's compaction status. Most of this data is quorum data related to votes that is rarely needed. These numbers do not include event data.
As one might imagine, handling such large, monolithic blocks of data is difficult.
In order to scale with the increasing storage requirements, we have decided to split the data into different parts and store them in different places. Frequently accessed parts need to be quickly available and well-indexed for querying, while parts only needed for archiving purposes can be stored differently.
Features
The original implementation focuses on performance. The data is organized in a key-value store, which allows nearly instant access via the provided index. While this is fast, it is not flexible and limits how users can query the data. This, in turn, limits the features available to users of the API. Furthermore, changing and extending the way the data is indexed is difficult.
To be able to provide the data in a more flexible and less labor-intensive way, we decided to use a solution that allows us to index the data in many ways and that allows us to change the indexing later on, if needed. Additionally, the new solution should provide API features that allow filtering and paging.
New solution
As previously mentioned, the solution to our challenges was to split the system into several specialized parts. To do so, we needed to:
Create new databases to store the data.
Create ingestion pipelines to transport the data.
Create a service to provide the new query API.
Handle the asynchronous nature of the new solution.
Modify the archiver to focus on processing.
The following sections will provide details for each of these items.
Data storage
We have different kind of data that needs different ways of access and therefore we decided to use different ways of storing the data. There is
Data that needs to be searchable and is frequently accessed.
Data that is mainly stored for historical reasons and backup, which is not frequently accessed.
Data that is temporarily stored for reprocessing if needed.
Searchable data
One of the hardest decision was to find a suitable database for the data that needs to be served frequently and with high performance, like transactions, tick data and events. We did experiment with several solutions from relational databases to online cloud solutions but they were not able to handle the expected amount of data well. Finally we decided to go with a search engine and to use Elasticsearch that is based on Apache Lucene but offers additional useful features for clustering and replication. One elasticsearch cluster consists out of at least three nodes to provide enough redundancy (for example for maintenance) and it's possible to have connected remote clusters in different data centers.
The most important searchable data is transaction and tick data. Events are also available but not in production yet. For each kind of searchable data there is one search index within elasticsearch. The index contains the source documents and the indexing information for data retrieval.
Technically, a search index is defined by a search template. The template describes the index, and any added data will be handled according to its description. To be able to change the index later, we use an alias to access every index. That way we can manage the data without having to change the clients. For example, we can re-index the data later with a new template version into another index. In principle, every index looks like this:
From the client perspective the data store looks like this:
Splitting the data and only storing the searchable data in elasticsearch drastically reduced the size of this part of the archive. For example we store (approximately) 160 million transactions with a dataset size of 90 GB, as well as 16 million ticks with a dataset size of 30 GB. This includes the source documents and the indices but not the replicated data (multiply by replication factor). Compared to the 600-800 GB for the full archive this is much easier to manage.
Archived data
For the data archive, we opted for a file storage system in which each epoch is stored as a data package. To make this possible we had to change the archiver to be able to split data per epoch and allow it to prune old data, keeping the overall data size manageable. The data is then shipped to a server where it is archived. Third parties can access the data there and import it. The archive is also useful as a backup.
The archive containing the per-epoch data is a work in progress that has not yet been completed. Currently, only complete data for all recorded epochs is available in a single database.
Temporary data
Between the source (collected data) and the destination (searchable data), there is a temporary data storage layer where we keep several epochs of collected data. This data can be replayed in case of data loss or processing bugs. For more details see the section about data ingestion.
Backup and disaster recovery
Several layers are in place to ensure that data can be restored in the event of a disaster. Regular snapshots of the systems allow us to restore them if something goes wrong. But it's also possible to restore from scratch. We have intermediary short term storage for replaying the last few epochs without the need of processing the source data again, as well as archived data that can be used to reimport old epochs.
Ingestion pipelines
Ingestion pipelines are used to transport the data from the source (for example the archiver or event service) to the destination (elasticsearch). The data publishing process must be decoupled from the source to prevent issues when the backend is unavailable. In theory, it would be possible to send the data directly from the publisher to elasticsearch, but we decided to further decouple it by using a messaging system to provide redundancy, temporary persistence, and the possibility to use data integration features or to scale up the processing with multiple partitions.
We chose to use Apache Kafka, an open-source distributed event streaming platform. A kafka cluster consists out of at least three nodes to provide proper redundancy.
A typical pipeline shipping data to elasticsearch looks like this:
The publisher (aka producer) collects the data from the source and sends messages to a kafka topic. A kafka topic is a queue of messages. A consumer reads the messages from kafka and sends the data to the destination.
Kafka allows multiple consumer groups to read from one topic and guarantees that each group consumes each message (ordered within one partition). That allows to consume one message in multiple ways. For example we could store the message and in parallel execute advanced data analytics on the incoming information.
We temporarily store around five epochs of data within kafka. In case of problems we can quickly replay parts of the data. For redundancy we use a replication factor of three, meaning that two nodes per cluster can go offline without affecting the data processing.
At the moment we have 3 ingestion pipelines running in production:
And one additional (events) in development:
The code can be found in the following repositories: go-data-publisher and for events in go-events-publisher and in go-events-consumer.
Query and status services
Due to decoupling, the data publishing process is asynchronous by nature. While this has some advantages, it also complicates the system on the query side because the archive and data collection parts are not synchronized.
Status Service
To solve problems with asynchronous ingestion and to provide metadata to the query service we created the status service that checks which data is already completely available in the data store. As an added benefit the service also verifies the ingested data. The status service mediates between the query service, the archiver and the searchable data. It ensures that only fully ingested data is served and also provides some metadata from the archiver that is not available in elasticsearch.
Another option would have been to use callbacks to notify us as soon as the data was ingested. We had already implemented this, but we decided to change it. We believe that querying the data from the status service makes the architecture easier to understand and maintain.
Query Service
The query service replaced the most important old endpoints transparently. These endpoints return the same data, but retrieve it from Elasticsearch. The query service also created new endpoints. These new endpoints allow to specify filters and ranges and provide a more general interface for pagination. You can find the documentation for the new v2 endpoints here and the openapi specs here.
We allow to retrieve the data paginated by offset. For performance reasons, it is necessary to restrict offset-based pagination. We allow a maximum of 10000 search results and one page cannot exceed 1024 items. The query service is hosted at https://api.qubic.org.
The flexibility of the new API is best illustrated with an example. For example, it is possible to query all burn transactions exceeding one million qubic, starting with tick number 25563000, by specifying filters and ranges:
Queries like these were not possible with the old endpoints. The new API allows third-party services to retrieve data much easier than before.
The new API will replace the old deprecated endpoints and the old ones will get removed soon. More information will follow in due time.
Modifications to the archiver
The go-archiver is still in use but it is going to be refactored step by step to focus more on collecting the data and short-term archiving. This is ongoing work that should be finished within the next few months. The new version is needed for completing the long term archive and backup.
The new version will have new features for managing the data per epoch:
It will produce one dataset per epoch for archiving.
It will enable re-importing a series of sequential epochs.
It will also prune old data as configured (for example keep last 'x' epochs).
Since the archiver is important to third-party developers and they do not want to run the complete integration infrastructure, many features will remain so that it can be used stand-alone with a basic API. However, certain query functionality must be removed due to changes in the data format.
Overall architecture
In summary, the following diagram provides an overview of the complete architecture as of the time this article was written.
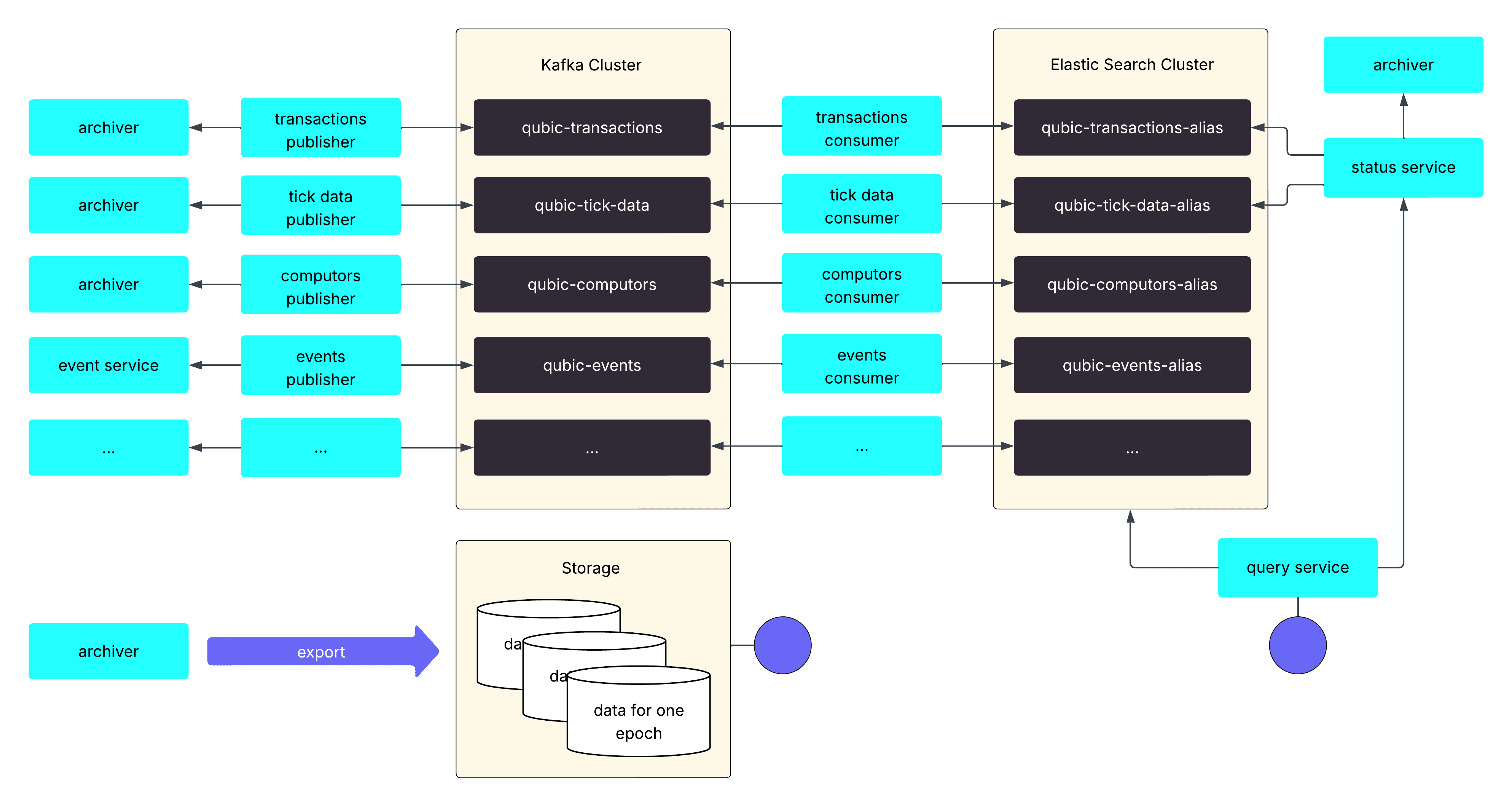
The first parts of the new solution went into production in April 2025 and over the following months it transparently replaced most of the old archiver endpoints. The full solution was available by the end of June 2025 and officially went live on July 1st, 2025. Some follow-up work, such as the archiver refactoring for the per-epoch archive, is planned until end of the year.
Summary
Qubic is advancing rapidly and is on the verge of becoming a mature project. To keep pace with its growth, we had to adapt the integration layer. Let's recall the challenges that we wanted to solve:
Load: We can confidently handle the expected load and scale up in the query, ingestion, and/or search layers.
Data: As the data is split, it is easier to manage now and the searchable data size is only a fraction of the total data. We are confident that we can process many more epochs until we need to scale up the search layer.
Features: Using elasticsearch provides us with a full-fledged search engine that offers all the features an API user could want. While we cannot expose all of these features because of performance and security reasons, the new API is much more flexible and extensible than the old one and it supports many new use cases.
We believe that the new architecture solves all the challenges we faced at the beginning of this year and that we are ready for Qubic's bright future.
Although these changes are not directly visible to the typical end user, they significantly impact users of the integration API and the integration layer's internals.
Our work is not finished, of course. A few more parts need to be completed and refined, and then we can focus on new tasks.
All of the code is open source and available on the qubic github repository. As always the developers and the community are eager to answer all your questions in the #dev channel on Discord.
Learn More & Get Involved
Ready to explore the Qubic ecosystem?
Start mining QUBIC at Useful Mining
Start learning at Qubic Academy
Join the community on X
Build on Qubic via our Discord Channel