
QUBIC BLOG POST
Bio-Inspired AI: How Neuromodulation Transforms Deep Neural Networks
Written by

The Qubic Team
Published:

Listen to this blog post

Analysis of Informing deep neural networks by multiscale
principles
In the brain, neuromodulation is the set of mechanisms through which certain neurotransmitters modify the functional properties of neurons and synapses, altering how they respond, for how long they integrate information, and under what conditions they change with experience.
These effects are produced mainly through neurotransmitters such as dopamine, serotonin, noradrenaline, and acetylcholine, which act on receptors known as metabotropic receptors. Unlike fast receptors, these do not directly generate an electrical signal, but instead activate cellular signaling pathways that modify the dynamic regime of the neuron and the circuit.
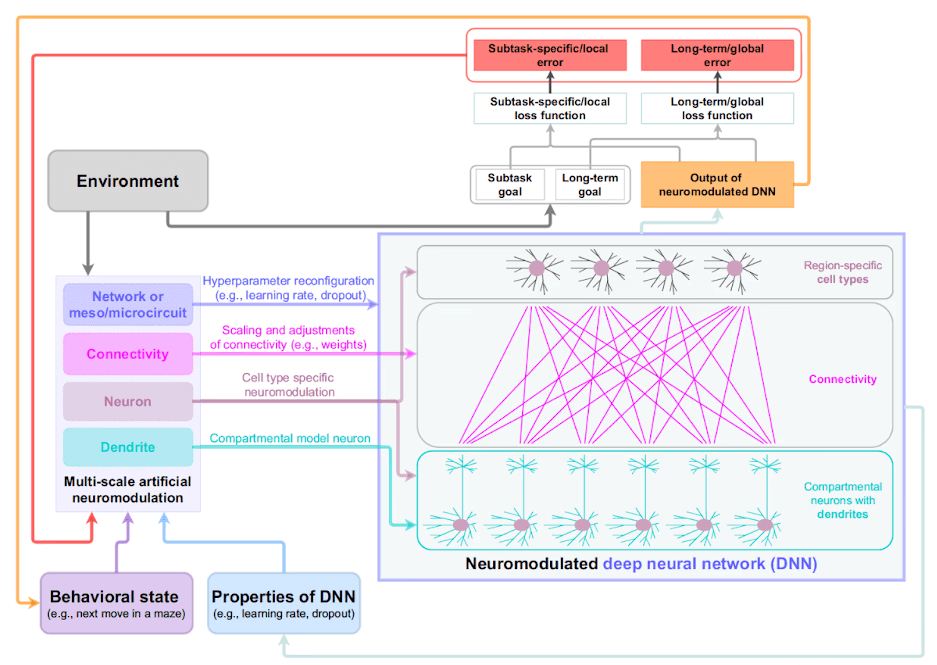
The article by Mei, Muller, and Ramaswamy published in Trends in Neurosciences starts from a well-known limitation of deep neural networks. These networks learn well in stable environments but adapt poorly when tasks change.
In response to this, the authors ask whether a bio-inspired model with neuromodulation could make artificial networks more adaptive. The central idea is to introduce signals that do not represent information about the environment, but that do regulate how the network learns, emulating how dopamine, serotonin, and others operate in biological systems.
Dynamic Learning Rate: A Bio-Inspired Approach to Adaptive Neural Networks
In deep neural networks, for learning to occur, the learning rate must be taken into account. This is the parameter that determines how much the weights of the network are modified when an error is made. A high value allows fast learning but makes the system unstable; a low value makes learning slow but more conservative.
We can see this with an example: Imagine that a very simple artificial neural network has a single weight that is used to decide whether an image contains a cat or not. That weight initially has a value of 0.5. The network makes a prediction, gets it wrong, and the algorithm calculates that in order to reduce the error that weight should decrease.
The key question is how much it should change, and that is determined by the learning rate. If the learning rate is high (for example 0.5), the adjustment is large: the weight can go from 0.5 to 0.0 in a single step. The network learns quickly, but these abrupt changes cause the weight to oscillate if subsequent examples push in opposite directions, making learning unstable.
If the learning rate is low (for example 0.01), the same error produces a small change and the weight goes from 0.5 to 0.49. The network learns more slowly, but in a progressive and stable way. In classical deep neural networks, this value is fixed before training begins and remains constant throughout the entire process, so the network always learns at the same speed.
Faced with such rigid learning, the article proposes that, analogously to brain neuromodulation, this parameter could vary dynamically depending on context, increasing in response to novelty or decreasing when stability is needed.
Dropout Regularization: A Simplified Model of Neural Variability
Another relevant concept they address is dropout. Imagine a neural network that always uses the same set of neurons to solve a task. Over time, the network becomes very efficient along that specific path, but also very fragile, because if that path stops working, performance drops sharply.
Dropout introduces a simple solution to this problem. During training, some neurons are randomly switched off, forcing the network to search for alternative routes to reach the result. In this way, the network learns to distribute information and becomes more robust.
The article interprets this mechanism as a very simplified equivalent of neuromodulation, since it does not change the content being processed, but rather which parts of the network participate at each moment, favoring more exploratory or more stable states depending on the need, although in a fixed way and without true contextual dynamics. The brain truly operates this way; it does not repeat activation patterns either over time or across space. There is variability that favors flexible behavior.
Modulated Synaptic Plasticity: Beyond Automatic Weight Updates
The article also discusses a third mechanism: modulated synaptic plasticity, that is, when and under what conditions the network's weights change in a lasting way.
In classical deep neural networks, plasticity is automatic because every error produces a weight update. However, in biological systems, the coincidence of activity between neurons does not guarantee learning. For a connection to strengthen or weaken, a specific neuromodulatory state is required, as if it were a signal of permission or veto.
The authors introduce a modulatory signal that authorizes or blocks weight updates, thus conditioning plasticity rather than the calculation of the error. The results of these approaches show measurable improvements in sequential learning and a reduction in catastrophic forgetting of previous tasks.
Limitations of Bio-Inspired Deep Learning in Atemporal Architectures
However, all of these advances occur within architectures that remain essentially atemporal. In the brain, neuromodulation acts on systems whose activity unfolds over time. In most deep neural networks, time is not part of the internal computation; it exists only as an external framework. The network is trained step by step, but during inference there are no states that evolve.
Therefore, although the authors introduce neuromodulation, what they actually do is adjust parameters of a static system, not modulate a living process.
In Transformers, this limitation is even greater. The attention mechanism is a mathematical operation that assigns relative weights to different parts of an input. It serves to decide which information is more relevant, but it does not introduce persistence or transitions between states. Time is symbolic, not dynamic.
For this reason, in bio-inspired neuromodulation of Transformers, what is really being done is the modulation of combinations of representations. There is no tonic activation, no latency, no learning during inference. Performance is improved, but the functional role it has in the brain is not reproduced.
Neuromodulation in Neuraxon: A Truly Dynamic Approach to Bio-Inspired AI
Neuraxon starts from a different premise. In its basic design, computation occurs in time, not over time. The system maintains internal states that evolve, even in the absence of clear external stimuli. Subthreshold activity, persistence, and transitions between states are part of the computation.
In this context, neuromodulation is not implemented as an external adjustment of parameters such as the learning rate or dropout, but as a direct modulation of internal dynamics.
Modulators influence how activity propagates, which patterns stabilize, and under what conditions the system becomes more plastic or more conservative.
The comparison with the brain is evident. We cannot reproduce cerebral complexity with thousands of receptors and an extremely complex anatomy. But what is preserved is what is essential, namely the dynamics of states. Learning occurs during the system's own operation, without separating training and inference.
In this sense, Neuraxon - Aigarth behave more like living systems than like networks trained in batches. Bio-inspired neuromodulation is part of the system, not a mathematical optimization mechanism. This aligns with Qubic's vision of decentralized AI built on Useful Proof of Work, where computing resources contribute meaningfully to AI training rather than arbitrary calculations.
References
Mei, J., Muller, E., & Ramaswamy, S. (2022). Informing deep neural networks by multiscale principles of neuromodulatory systems. Trends in Neurosciences, 45(3), 237-250.
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: A simple way to prevent neural networks from overfitting. Journal of Machine Learning Research, 15(1), 1929-1958.
Kirkpatrick, J., et al. (2017). Overcoming catastrophic forgetting in neural networks. PNAS, 114(13), 3521-3526.
Bromberg-Martin, E. S., Matsumoto, M., & Hikosaka, O. (2010). Dopamine in motivational control: rewarding, aversive, and alerting. Neuron, 68(5), 815-834.
Glimcher, P. W. (2011). Understanding dopamine and reinforcement learning: The dopamine reward prediction error hypothesis. PNAS, 108(Supplement 3), 15647-15654.
Schmidgall, S., et al. (2024). Brain-inspired learning in artificial neural networks: A review. APL Machine Learning, 2(2), 021501.
Vaswani, A., et al. (2017). Attention Is All You Need. Advances in Neural Information Processing Systems, 30.
Join the Discussion
Have thoughts on bio-inspired AI and the future of neuromodulation in neural networks? We'd love to hear from you! Connect with the Qubic community:
Discord: discord.gg/qubic
X (Twitter): @_Qubic_
Telegram: t.me/qubic_community
Building the future of decentralized AI at Qubic