
POST NO BLOG QUBIC
Atualização da Funcionalidade da Camada de Integração Qubic 2.0
Escrito por

A Equipe Qubic
Publicado:
1 de ago. de 2025

Ouça este post do blog
Reforma da Camada de Integração
Há um tempo, a Qubic tinha uma "camada de integração" que facilita para aplicativos externos, como carteiras de criptomoedas, câmbios e exploradores de blocos, se conectarem à sua rede. Esta camada permite que esses aplicativos realizem coisas importantes, como enviar transações, verificar contratos inteligentes e obter informações sobre o que está acontecendo na rede Qubic. É realmente útil, pois os desenvolvedores não precisam aprender todas as complicadas funcionalidades internas da Qubic ou descobrir como se comunicar diretamente com os seus "nós" (os computadores que executam a rede).
No entanto, a Qubic está crescendo rápido, e essa antiga camada de integração estava começando a atingir seus limites. Para acompanhar o crescimento futuro, a Qubic começou a reconstruir essa camada no início do ano. O resultado é uma grande atualização, incluindo uma nova maneira de armazenar dados históricos e APIs melhoradas. Este novo sistema foi projetado para lidar com o crescimento esperado da Qubic. Foi lançado oficialmente em 1º de julho de 2025.
Embora alguns dos detalhes técnicos possam não ser super interessantes para o usuário médio da Qubic, esta nova configuração é uma grande mudança nos bastidores. Ajuda a garantir que tudo funcione sem problemas à medida que a Qubic continua a expandir.
APIs de Integração
A camada de integração fornece várias APIs diferentes. As mais importantes são a API ao vivo e a API de arquivo.
A API ao vivo se comunica diretamente com os nós da Qubic e fornece os dados mais atuais. Ela busca informações como saldos e dados de ativos, e permite que os usuários enviem transações e consultem contratos inteligentes. Os nós fornecem uma visão atualizada dos dados para a época atual. A API ao vivo permanecerá inalterada.
A API de arquivo fornece dados arquivados. Esses dados são coletados dos nós e armazenados em um banco de dados. Esta API será substituída pela nova API de arquivo.
Solução Original
A implementação original de arquivo (qubic-archiver) é uma solução rápida, monolítica e especializada. Ela processa os dados para cada tick, valida usando dados de quórum, armazena em um banco de dados embutido (pebble) e fornece via GRPC e endpoints semelhantes ao REST. A redundância é alcançada executando várias instâncias em diferentes data centers em paralelo. Embora esta solução ainda funcione perfeitamente, ela não é suficientemente à prova de futuro para lidar com o crescimento esperado a longo prazo.
Certos desafios precisam ser resolvidos para garantir a sustentabilidade a longo prazo. Os mais importantes são:
Carga => Conseguir escalar com o crescente número de requisições de API.
Dados => Conseguir lidar com grandes quantidades de dados.
Características => Conseguir fornecer melhor acesso aos dados.
Carga
Não faz muito tempo, no início de 2025, a camada de integração toda precisava lidar com até 10.000 requisições por minuto. Apenas seis meses depois, esse número dobrou, e agora servimos mais de 20.000 requisições por minuto durante os horários de pico. Essa carga deve crescer à medida que o projeto Qubic ganha cada vez mais adoção. Além disso, o processamento se tornou mais intensivo em recursos à medida que o tempo de tick diminuiu e mais transações foram feitas.
Para escalar conforme necessário, decidimos dividir a parte de consulta em uma aplicação separada, permitindo que ela se concentre em servir requisições enquanto o arquivador se concentra em processar dados.
Dados
Enquanto um ano atrás a quantidade de dados que coletávamos era facilmente gerenciável, agora armazenamos entre 600 GB e 800 GB de dados por instância de arquivador, dependendo do status de compactação do banco de dados. A maior parte desses dados é relacionada a quóruns de votos que raramente são necessários. Esses números não incluem dados de eventos.
Como se pode imaginar, lidar com tais grandes blocos monolíticos de dados é difícil.
Para escalar com os crescentes requisitos de armazenamento, decidimos dividir os dados em partes diferentes e armazená-los em lugares diferentes. As partes frequentemente acessadas precisam estar rapidamente disponíveis e bem indexadas para consulta, enquanto partes somente necessárias para fins de arquivamento podem ser armazenadas de forma diferente.
Características
A implementação original foca no desempenho. Os dados são organizados em um armazenamento de chave-valor, o que permite acesso quase instantâneo via o índice fornecido. Embora isso seja rápido, não é flexível e limita como os usuários podem consultar os dados. Isso, por sua vez, limita as funcionalidades disponíveis para os usuários da API. Além disso, mudar e estender a maneira como os dados são indexados é difícil.
Para conseguir fornecer os dados de uma maneira mais flexível e menos trabalhosa, decidimos usar uma solução que nos permite indexar os dados de muitas maneiras e que nos possibilita mudar o índice mais tarde, se necessário. Além disso, a nova solução deve fornecer recursos da API que permitam filtragem e paginação.
Nova Solução
Como mencionado anteriormente, a solução para nossos desafios foi dividir o sistema em várias partes especializadas. Para isso, precisávamos:
Criar novos bancos de dados para armazenar os dados.
Criar pipelines de ingestão para transportar os dados.
Criar um serviço para fornecer a nova API de consulta.
Lidar com a natureza assíncrona da nova solução.
Modificar o arquivador para se concentrar no processamento.
As seções seguintes fornecerão detalhes para cada um desses itens.
Armazenamento de Dados
Temos diferentes tipos de dados que precisam de diferentes formas de acesso e, portanto, decidimos usar diferentes maneiras de armazenar os dados. Há
Dados que precisam ser pesquisáveis e são frequentemente acessados.
Dados que são armazenados principalmente por motivos históricos e de backup, que não são acessados com frequência.
Dados que são temporariamente armazenados para reprocessamento, se necessário.
Dados Pesquisáveis
Uma das decisões mais difíceis foi encontrar um banco de dados adequado para os dados que precisam ser servidos frequentemente e com alto desempenho, como transações, dados de tick e eventos. Experimentamos várias soluções, desde bancos de dados relacionais até soluções em nuvem online, mas nenhum conseguiu lidar bem com a quantidade esperada de dados. Finalmente, decidimos usar um motor de busca e utilizar Elasticsearch, que é baseado em Apache Lucene, mas oferece recursos adicionais úteis para agrupamento e replicação. Um cluster do Elasticsearch consiste em pelo menos três nós para fornecer redundância suficiente (por exemplo, para manutenção) e é possível ter clusters remotos conectados em diferentes data centers.
Os dados pesquisáveis mais importantes são dados de transações e de ticks. Eventos também estão disponíveis, mas ainda não estão em produção. Para cada tipo de dado pesquisável, existe um índice de pesquisa dentro do Elasticsearch. O índice contém os documentos de origem e as informações de indexação para recuperação de dados.
Tecnicamente, um índice de pesquisa é definido por um modelo de pesquisa. O modelo descreve o índice, e qualquer dado adicionado será tratado de acordo com sua descrição. Para podermos mudar o índice mais tarde, usamos um alias para acessar cada índice. Assim, podemos gerenciar os dados sem precisar mudar os clientes. Por exemplo, podemos reindexar os dados mais tarde com uma nova versão do modelo em outro índice. Em princípio, cada índice parece com isso:
Da perspectiva do cliente, o armazenamento de dados parece assim:
Dividir os dados e armazenar apenas os dados pesquisáveis no Elasticsearch reduziu drasticamente o tamanho dessa parte do arquivo. Por exemplo, armazenamos (aproximadamente) 160 milhões de transações com um tamanho de conjunto de dados de 90 GB, bem como 16 milhões de ticks com um tamanho de conjunto de dados de 30 GB. Isso inclui os documentos de origem e os índices, mas não os dados replicados (multiplicar pelo fator de replicação). Em comparação com os 600-800 GB para o arquivo completo, isso é muito mais fácil de gerenciar.
Dados Arquivados
Para o arquivo de dados, optamos por um sistema de armazenamento de arquivos no qual cada época é armazenada como um pacote de dados. Para tornar isso possível, tivemos que mudar o arquivador para ser capaz de dividir os dados por época e permitir que ele elimine dados antigos, mantendo o tamanho geral dos dados gerenciável. Os dados são então enviados para um servidor onde são arquivados. Terceiros podem acessar os dados lá e importá-los. O arquivo também é útil como um backup.
O arquivo que contém os dados por época é uma obra em progresso que ainda não foi concluída. Atualmente, apenas dados completos de todas as épocas registradas estão disponíveis em um único banco de dados.
Dados Temporários
Entre a origem (dados coletados) e o destino (dados pesquisáveis), há uma camada de armazenamento de dados temporários onde mantemos várias épocas de dados coletados. Esses dados podem ser reproduzidos em caso de perda de dados ou bugs de processamento. Para mais detalhes, consulte a seção sobre ingestão de dados.
Backup e recuperação de desastres
Várias camadas estão em vigor para garantir que os dados possam ser restaurados em caso de desastre. Capturas regulares dos sistemas nos permitem restaurá-los se algo der errado. Mas também é possível restaurar do zero. Temos armazenamento intermediário de curto prazo para reproduzir as últimas várias épocas sem a necessidade de processar os dados de origem novamente, bem como dados arquivados que podem ser usados para reimportar épocas antigas.
Pipelines de Ingestão
Pipelines de ingestão são usados para transportar os dados da origem (por exemplo, o arquivador ou o serviço de eventos) para o destino (Elasticsearch). O processo de publicação de dados deve ser desacoplado da origem para evitar problemas quando o backend não estiver disponível. Em teoria, seria possível enviar os dados diretamente do publicador para o Elasticsearch, mas decidimos desacoplar ainda mais usando um sistema de mensagens para fornecer redundância, persistência temporária e a possibilidade de usar recursos de integração de dados ou escalar o processamento com várias partições.
Escolhemos usar Apache Kafka, uma plataforma de streaming de eventos distribuída de código aberto. Um cluster do Kafka consiste em pelo menos três nós para fornecer a redundância adequada.
Um pipeline típico que envia dados para o Elasticsearch se parece com isso:
O publicador (também conhecido como produtor) coleta os dados da origem e envia mensagens para um tópico do Kafka. Um tópico do Kafka é uma fila de mensagens. Um consumidor lê as mensagens do Kafka e envia os dados para o destino.
O Kafka permite que vários grupos de consumidores leiam de um tópico e garante que cada grupo consuma cada mensagem (ordenada dentro de uma partição). Isso permite consumir uma mensagem de várias maneiras. Por exemplo, poderíamos armazenar a mensagem e, em paralelo, executar análises avançadas de dados sobre as informações recebidas.
Armazenamos temporariamente cerca de cinco épocas de dados dentro do Kafka. Em caso de problemas, podemos rapidamente reproduzir partes dos dados. Para redundância, usamos um fator de replicação de três, o que significa que dois nós por cluster podem ficar offline sem afetar o processamento de dados.
No momento, temos 3 pipelines de ingestão em produção:
E um adicional (eventos) em desenvolvimento:
O código pode ser encontrado nos seguintes repositórios: go-data-publisher e para eventos em go-events-publisher e em go-events-consumer.
Serviços de Consulta e Status
Devido ao desacoplamento, o processo de publicação de dados é assíncrono por natureza. Embora isso tenha algumas vantagens, também complica o sistema do lado da consulta, porque as partes do arquivo e da coleta de dados não estão sincronizadas.
Serviço de Status
Para resolver problemas com a ingestão assíncrona e fornecer metadados ao serviço de consulta, criamos o serviço de status que verifica quais dados já estão completamente disponíveis no armazenamento de dados. Como benefício adicional, o serviço também verifica os dados ingeridos. O serviço de status atua como intermediário entre o serviço de consulta, o arquivador e os dados pesquisáveis. Ele garante que apenas dados completamente ingeridos sejam servidos e também fornece alguns metadados do arquivador que não estão disponíveis no Elasticsearch.
Outra opção teria sido usar callbacks para nos notificar assim que os dados fossem ingeridos. Já tínhamos implementado isso, mas decidimos mudar. Acreditamos que consultar os dados a partir do serviço de status torna a arquitetura mais fácil de entender e manter.
Serviço de Consulta
O serviço de consulta substituiu os endpoints antigos mais importantes de forma transparente. Esses endpoints retornam os mesmos dados, mas os recuperam do Elasticsearch. O serviço de consulta também criou novos endpoints. Esses novos endpoints permitem especificar filtros e faixas e fornecem uma interface mais geral para paginação. Você pode encontrar a documentação para os novos endpoints v2 aqui e as especificações openapi aqui.
Permitimos recuperar os dados paginados por offset. Por razões de desempenho, é necessário restringir a paginação baseada em offset. Permitimos um máximo de 10.000 resultados de pesquisa e uma página não pode exceder 1024 itens. O serviço de consulta está hospedado em https://api.qubic.org.
A flexibilidade da nova API é melhor ilustrada com um exemplo. Por exemplo, é possível consultar todas as transações de queima que excedem um milhão de qubits, começando a partir do número do tick 25563000, especificando filtros e faixas:
Consultas como essas não eram possíveis com os antigos endpoints. A nova API permite que serviços de terceiros recuperem dados de maneira muito mais fácil do que antes.
A nova API substituirá os antigos endpoints obsoletos e os antigos serão removidos em breve. Mais informações seguirão a seu tempo.
Modificações no Arquivador
O go-archiver ainda está em uso, mas está sendo refatorado passo a passo para se concentrar mais na coleta de dados e no arquivamento de curto prazo. Esse trabalho está em andamento e deve ser concluído nos próximos meses. A nova versão é necessária para finalizar o arquivo e backup de longo prazo.
A nova versão terá novos recursos para gerenciar os dados por época:
Produzirá um conjunto de dados por época para arquivamento.
Permitirá reimportar uma série de épocas sequenciais.
Também eliminará dados antigos conforme configurado (por exemplo, manter as últimas 'x' épocas).
Como o arquivador é importante para desenvolvedores terceiros e eles não desejam rodar toda a infraestrutura de integração, muitos recursos permanecerão para que ele possa ser usado de forma independente com uma API básica. No entanto, certas funcionalidades de consulta devem ser removidas devido a mudanças no formato dos dados.
Arquitetura Geral
Em resumo, o seguinte diagrama fornece uma visão geral da arquitetura completa até o momento em que este artigo foi escrito.
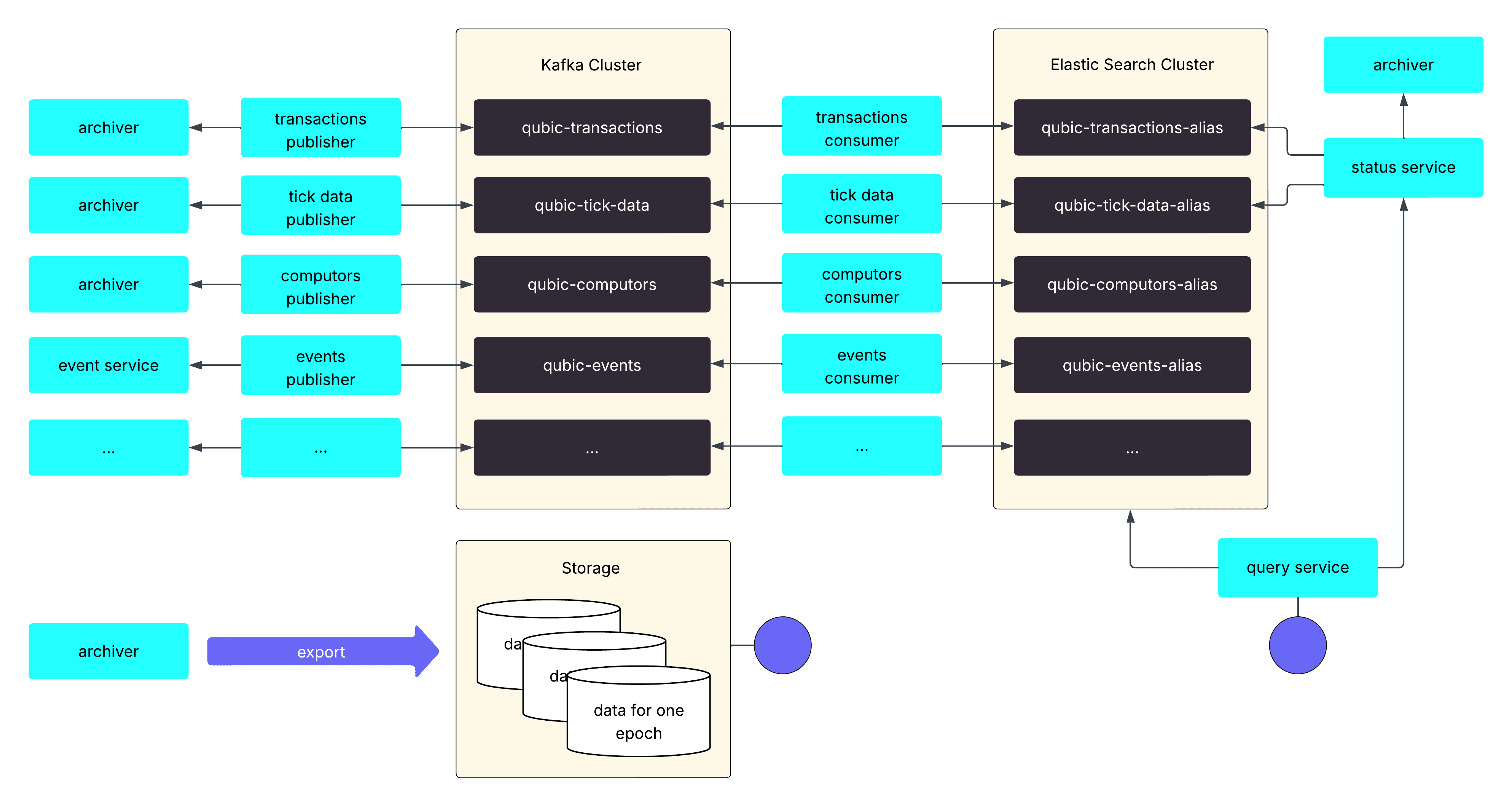
As primeiras partes da nova solução foram para produção em abril de 2025 e, ao longo dos meses seguintes, substituíram de forma transparente a maioria dos antigos endpoints do arquivador. A solução completa estava disponível até o final de junho de 2025 e foi oficialmente lançada em 1º de julho de 2025. Alguns trabalhos de acompanhamento, como a refatoração do arquivador para o arquivo por época, estão planejados até o final do ano.
Resumo
A Qubic está avançando rapidamente e está à beira de se tornar um projeto maduro. Para acompanhar seu crescimento, tivemos que adaptar a camada de integração. Vamos relembrar os desafios que queríamos resolver:
Carga: Podemos lidar com a carga esperada com confiança e escalar nas camadas de consulta, ingestão e/ou busca.
Dados: Como os dados estão divididos, é mais fácil gerenciá-los agora, e o tamanho dos dados pesquisáveis é apenas uma fração do total. Estamos confiantes de que podemos processar muitas mais épocas até precisarmos escalar a camada de busca.
Características: Usar o Elasticsearch nos fornece um mecanismo de busca completo que oferece todos os recursos que um usuário da API poderia desejar. Embora não possamos expor todos esses recursos devido a razões de desempenho e segurança, a nova API é muito mais flexível e extensível do que a antiga e suporta muitos novos casos de uso.
Acreditamos que a nova arquitetura resolve todos os desafios que enfrentamos no início deste ano e que estamos prontos para o brilhante futuro da Qubic.
Embora essas mudanças não sejam visíveis diretamente para o típico usuário final, elas impactam significativamente os usuários da API de integração e as internas da camada de integração.
Nosso trabalho não está terminado, é claro. Mais algumas partes precisam ser concluídas e refinadas, e então poderemos nos concentrar em novas tarefas.
Todo o código é open source e está disponível no repositório do github da qubic. Como sempre, os desenvolvedores e a comunidade estão ansiosos para responder a todas as suas perguntas no canal #dev do Discord.
Saiba Mais & Participe
Pronto para explorar o ecossistema Qubic?
Comece a minerar QUBIC em Útil Mining
Comece a aprender em Qubic Academy
Junte-se à comunidade em X
Construa no Qubic através do nosso canal do Discord