
POST NO BLOG QUBIC
IA Inspirada na Biologia: Como a Neuromodulação Transforma Redes Neurais Profundas
Escrito por

A Equipe Qubic
Publicado:
4 de fev. de 2026

Ouça este post do blog

Análise da Informar redes neurais profundas por princípios multiescalares
sistemas neuromodulatórios
No cérebro, a neuromodulação é o conjunto de mecanismos pelos quais certos neurotransmissores modificam as propriedades funcionais dos neurônios e sinapses, alterando como eles respondem, por quanto tempo integram informações e sob quais condições mudam com a experiência.
Esses efeitos são produzidos principalmente por neurotransmissores como dopamina, serotonina, norepinefrina e acetilcolina, que agem em receptores conhecidos como receptores metabotrópicos. Diferentemente dos receptores rápidos, estes não geram diretamente um sinal elétrico, mas, em vez disso, ativam vias de sinalização celular que modificam o regime dinâmico do neurônio e do circuito.
O artigo de Mei, Muller e Ramaswamy publicado em Trends in Neurosciences parte de uma limitação bem conhecida das redes neurais profundas. Essas redes aprendem bem em ambientes estáveis, mas se adaptam mal quando as tarefas mudam.
Em resposta a isso, os autores perguntam se um modelo bioinspirado com neuromodulação poderia tornar as redes artificiais mais adaptativas. A ideia central é introduzir sinais que não representam informações sobre o ambiente, mas que regulam como a rede aprende, emulando como a dopamina, serotonina e outros operam em sistemas biológicos.
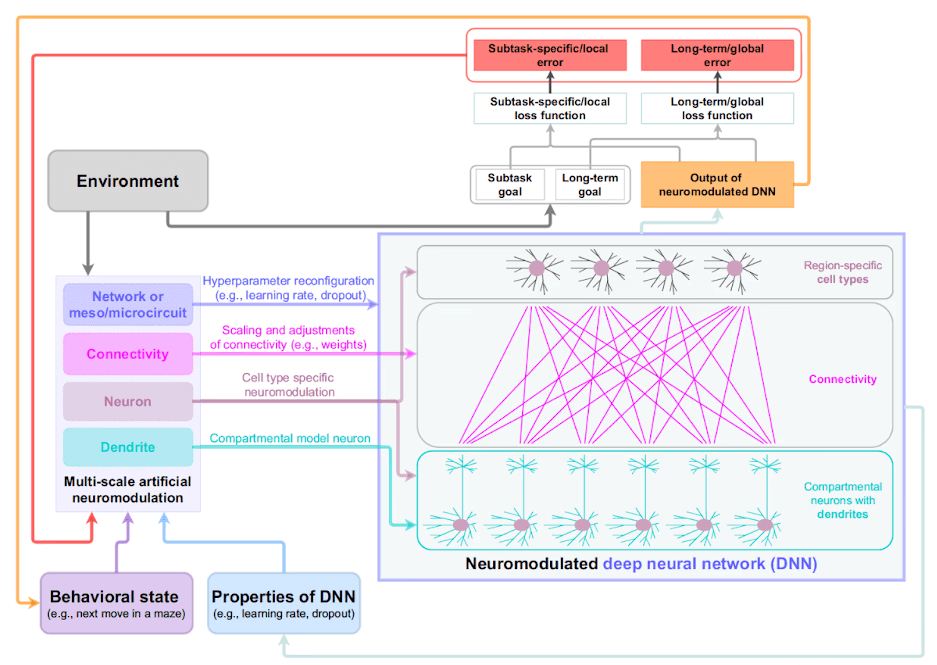
Taxa de Aprendizado Dinâmica: Uma Abordagem Bio-Inspirada para Redes Neurais Adaptativas
Em redes neurais profundas, para que a aprendizagem ocorra, a taxa de aprendizado deve ser levada em consideração. Este é o parâmetro que determina quanto os pesos da rede são modificados quando um erro é cometido. Um valor alto permite uma aprendizagem rápida, mas torna o sistema instável; um valor baixo torna a aprendizagem lenta, mas mais conservadora.
Podemos ver isso com um exemplo: imagine que uma rede neural artificial muito simples tem um único peso que é usado para decidir se uma imagem contém um gato ou não. Esse peso inicialmente tem um valor de 0,5. A rede faz uma previsão, erra e o algoritmo calcula que, para reduzir o erro, aquele peso deve diminuir.
A questão chave é quanto ele deve mudar, e isso é determinado pela taxa de aprendizado. Se a taxa de aprendizado for alta (por exemplo, 0,5), o ajuste é grande: o peso pode ir de 0,5 para 0,0 em um único passo. A rede aprende rapidamente, mas essas mudanças abruptas fazem com que o peso oscile se exemplos subsequentes empurrarem em direções opostas, tornando a aprendizagem instável.
Se a taxa de aprendizado for baixa (por exemplo, 0,01), o mesmo erro produz uma pequena mudança e o peso vai de 0,5 para 0,49. A rede aprende mais lentamente, mas de maneira progressiva e estável. Nas redes neurais profundas clássicas, esse valor é fixado antes do início do treinamento e permanece constante durante todo o processo, de modo que a rede aprende sempre à mesma velocidade.
Diante de uma aprendizagem tão rígida, o artigo propõe que, analogamente à neuromodulação cerebral, esse parâmetro poderia variar dinamicamente dependendo do contexto, aumentando em resposta a novidades ou diminuindo quando a estabilidade é necessária.
Regularização por Dropout: Um Modelo Simplificado de Variabilidade Neural
Outro conceito relevante que abordam é dropout. Imagine uma rede neural que sempre usa o mesmo conjunto de neurônios para resolver uma tarefa. Com o tempo, a rede se torna muito eficiente ao longo desse caminho específico, mas também muito frágil, porque se esse caminho parar de funcionar, o desempenho despenca.
O dropout introduz uma solução simples para esse problema. Durante o treinamento, alguns neurônios são desligados aleatoriamente, forçando a rede a buscar rotas alternativas para chegar ao resultado. Dessa forma, a rede aprende a distribuir informações e se torna mais robusta.
O artigo interpreta esse mecanismo como um equivalente muito simplificado da neuromodulação, uma vez que não altera o conteúdo que está sendo processado, mas sim quais partes da rede participam em cada momento, favorecendo estados mais exploratórios ou mais estáveis dependendo da necessidade, embora de forma fixa e sem verdadeiras dinâmicas contextuais. O cérebro opera verdadeiramente dessa maneira; não repete padrões de ativação nem ao longo do tempo nem através do espaço. Há variabilidade que favorece um comportamento flexível.
Plasticidade Sináptica Modulada: Além das Atualizações Automáticas de Pesos
O artigo também discute um terceiro mecanismo: plasticidade sináptica modulada, isto é, quando e sob quais condições os pesos da rede mudam de forma duradoura.
Nas redes neurais profundas clássicas, a plasticidade é automática porque todo erro produz uma atualização de peso. No entanto, em sistemas biológicos, a coincidência de atividade entre neurônios não garante aprendizagem. Para que uma conexão se fortaleça ou enfraqueça, é necessário um estado neuromodulatório específico, como se fosse um sinal de permissão ou veto.
Os autores introduzem um sinal modulatório que autoriza ou bloqueia atualizações de peso, condicionando assim a plasticidade em vez do cálculo do erro. Os resultados dessas abordagens mostram melhorias mensuráveis na aprendizagem sequencial e uma redução no esquecimento catastrófico de tarefas anteriores.
Limitações do Aprendizado Profundo Bio-Inspirado em Arquiteturas Atemporais
No entanto, todos esses avanços ocorrem dentro de arquiteturas que permanecem essencialmente atemporais. No cérebro, a neuromodulação atua em sistemas cuja atividade se desenrola ao longo do tempo. Na maioria das redes neurais profundas, o tempo não faz parte do cálculo interno; ele existe apenas como uma estrutura externa. A rede é treinada passo a passo, mas durante a inferência não há estados que evoluem.
Portanto, embora os autores introduzam a neuromodulação, o que realmente fazem é ajustar parâmetros de um sistema estático, não modular um processo vivo.
Em Transformers, essa limitação é ainda maior. O mecanismo de atenção é uma operação matemática que atribui pesos relativos a diferentes partes de uma entrada. Ele serve para decidir qual informação é mais relevante, mas não introduz persistência ou transições entre estados. O tempo é simbólico, não dinâmico.
Por essa razão, na neuromodulação bio-inspirada dos Transformers, o que se está realmente fazendo é a modulação de combinações de representações. Não há ativação tônica, nem latência, nem aprendizado durante a inferência. O desempenho é melhorado, mas o papel funcional que tem no cérebro não é reproduzido.
Neuromodulação na Neuraxon: Uma Abordagem Verdadeiramente Dinâmica para IA Bio-Inspirada
Neuraxon parte de uma premissa diferente. Em seu design básico, o cálculo ocorre no tempo, não ao longo do tempo. O sistema mantém estados internos que evoluem, mesmo na ausência de estímulos externos claros. Atividade sub-limiar, persistência e transições entre estados fazem parte do cálculo.
Nesse contexto, a neuromodulação não é implementada como um ajuste externo de parâmetros, como a taxa de aprendizado ou o dropout, mas como uma modulação direta das dinâmicas internas.
Moduladores influenciam como a atividade se propaga, quais padrões se estabilizam e sob quais condições o sistema se torna mais plástico ou mais conservador.
A comparação com o cérebro é evidente. Não podemos reproduzir a complexidade cerebral com milhares de receptores e uma anatomia extremamente complexa. Mas o que é preservado é o que é essencial, ou seja, a dinâmica dos estados. O aprendizado ocorre durante a operação do próprio sistema, sem separar treinamento e inferência.
Nesse sentido, Neuraxon - Aigarth se comporta mais como sistemas vivos do que como redes treinadas em lotes. A neuromodulação bio-inspirada é parte do sistema, não um mecanismo de otimização matemática. Isso se alinha com a visão da Qubic sobre IA descentralizada construída sobre Prova de Trabalho Útil, onde recursos computacionais contribuem de forma significativa para o treinamento de IA em vez de cálculos arbitrários.
Referências
Mei, J., Muller, E., & Ramaswamy, S. (2022). Informar redes neurais profundas por princípios multiescalares de sistemas neuromodulatórios. Trends in Neurosciences, 45(3), 237-250.
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: Uma maneira simples de evitar que redes neurais se ajustem demais. Journal of Machine Learning Research, 15(1), 1929-1958.
Kirkpatrick, J., et al. (2017). Superando o esquecimento catastrófico em redes neurais. PNAS, 114(13), 3521-3526.
Bromberg-Martin, E. S., Matsumoto, M., & Hikosaka, O. (2010). Dopamina no controle motivacional: recompensa, aversão e alerta. Neuron, 68(5), 815-834.
Glimcher, P. W. (2011). Compreendendo dopamina e aprendizagem por reforço: A hipótese do erro de previsão de recompensa da dopamina. PNAS, 108(Suplemento 3), 15647-15654.
Schmidgall, S., et al. (2024). Aprendizado inspirado no cérebro em redes neurais artificiais: Uma revisão. APL Machine Learning, 2(2), 021501.
Vaswani, A., et al. (2017). Atenção é tudo que você precisa. Advances in Neural Information Processing Systems, 30.
Participe da Discussão
Tem pensamentos sobre IA bio-inspirada e o futuro da neuromodulação em redes neurais? Adoraríamos ouvir de você! Conecte-se com a comunidade Qubic:
Discord: discord.gg/qubic
X (Twitter): @_Qubic_
Telegram: t.me/qubic_community
Construindo o futuro da IA descentralizada em Qubic